이 포스트는 LeetCode에서 Queue, Stack 튜토리얼을 읽으면서 배운 내용을 기록하고 있다.
Explore - LeetCode
LeetCode Explore is the best place for everyone to start practicing and learning on LeetCode. No matter if you are a beginner or a master, there are always new topics waiting for you to explore.
leetcode.com
Queue
Queue, 큐는 대표적인 FIFO 자료구조로 Stack과 더불어 유명한 선형 자료구조다. FIFO는 말 그대로 First-In-First-Out으로 먼저 자료구조에 삽입된 데이터가 먼저 자료구조에서 삭제된다. 큐에서는 이 삽입, 삭제를 enqueue, dequeue라고 부른다.
만약 단순하게 큐를 구현하고자 한다면 공간이 늘어나는 동적 배열(Java의 ArrayList)과 데이터를 삭제할 위치를 가리키는 포인터를 멤버로 가지는 클래스를 구현하면 될 것이다. 하지만 이 경우 단순히 삽입 삭제만 반복해도 동적 배열은 무한정 늘어나면서 포인터가 지나간 위치는 할당됐지만 사용할 수 없는 상태가 된다.

앞의 1, 2가 저장됐던 공간은 포인터가 지나가면서 사용할 수 없지만 공간은 할당되어 있는 낭비가 발생하는데 만약 큐의 크기가 제한되어 있다면 원형 큐(Circular Queue)를 구현하여 해결할 수 있다.

원형 큐는 동일하게 배열과 포인터 두 개를 사용해서 구현할 수 있다. 두 포인터는 각각 삽입, 삭제가 발생할 위치를 가리키고 있다. 그리고 삽입 포인터나 삭제 포인터가 배열의 끝을 넘어간다면 다시 배열의 첫 원소를 가리키게 된다. 이를 활용하여 이전에 할당했던 공간을 낭비하지 않고 사용할 수 있다.
원형 큐를 구현할 때는 다음과 같은 로직을 구현해야 한다.
-
삽입(enqueue)
-
삭제(dequeue)
-
포화 상태 확인(isFull)
-
공백 상태 확인(isEmpty)
이때 배열에 대하여 포인터를 사용하기 때문에 맨 처음 포인터의 시작 위치나 삽입, 삭제 시 head, tail 포인터의 이동 방향, 그리고 포화, 공백 상태를 확인할 때 이 포인터를 어떻게 활용할 것인지에 대한 고민이 필요하다. 먼저 기본적인 원리는 큐의 두 포인터를 배열 밖의 인덱스로 초기화하는 것이다.
public MyCircularQueue(int k) {
queue = new int[k];
head = -1;
tail = -2;
size = k;
}head 포인터는 큐가 삽입되는 곳을, tail 포인터는 큐에서 삭제되는 곳을 가리키고 있다. 이때 -1, -2는 배열에서 접근할 수 없는 곳이기 때문에 포인터가 이곳에 있는지 확인하여 현재 큐의 상태(공백)를 확인할 수 있다.
그렇다면 왜 포인터를 0으로 두지 않고 굳이 -1, -2로 두는 것일까? 이는 구현 방식에 따라 다르겠지만 현재 두 포인터를 활용하는 방식은 다음과 같다.
-
삽입: head 포인터가 가리키는 곳에 데이터를 삽입 후 head 포인터 증가.
-
삭제: tail 포인터 증가(필요시 tail 포인터가 가리키는 곳의 데이터 반환).
-
포화 상태 확인: head 포인터와 tail 포인터가 가리키는 곳이 같음.
-
공백 상태 확인: head 포인터와 tail 포인터가 -1을 가리키고 있음.
큐에 데이터를 삽입할 경우 head 포인터는 1씩 증가하며 데이터를 삭제할 경우 tail 포인터는 1씩 증가한다. 그런데 데이터를 삽입 후 head 포인터가 tail 포인터를 만난다면 무슨 상황일까? 이는 더 이상 큐에 들어갈 자리가 없다는 것을 의미한다. 왜냐면 삽입 연산 시 head 포인터가 가리키는 곳에 데이터를 저장하고 head 포인터를 증가시켜야 하는데 현재 tail 포인터가 가리키는 곳은 삭제 연산이 일어났을 때 처리될 곳이기 때문이다.

반대로 데이터를 삭제 후 tail 포인터가 head 포인터를 만난다면 무슨 상황일까? 이는 큐에 아무런 데이터도 없다는 것을 의미한다. 왜냐면 삭제 연산 시 tail 포인터가 가리키는 곳의 데이터를 필요에 따라 반환하고 tail 포인터를 증가시켜야 하는데 현재 head 포인터가 가리키고 있는 곳은 데이터 삽입 시 저장될 곳이기 때문이다.
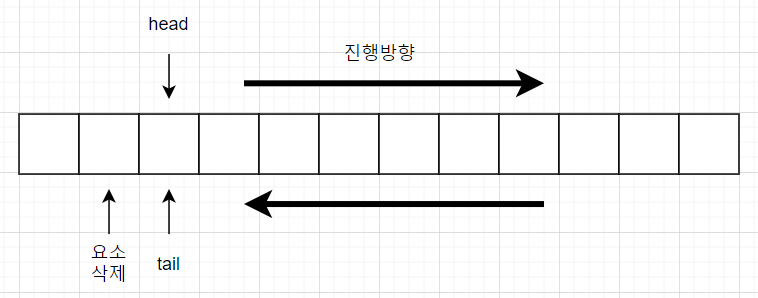
삽입, 삭제 연산 시 head 포인터와 tail 포인터가 만난다면 즉 같은 곳을 가리키게 된다면 이는 큐가 비어있거나 꽉찼다는 것을 의미하는데 이를 이 포인터만 가지고 어떻게 구분할 수 있을까? 삽입, 삭제 연산 시에는 어느 포인터가 움직여서 이 두 포인터가 만났는지 알 수 있지만 나중에 큐의 포화 상태나 공백 상태를 확인할 때는 따로 기억하고 있지 않는 이상 어떤 포인터가 움직여서 만나게 된 건지 구분할 수 없다. 즉 큐가 포화상태라서 같은 곳을 가리키고 있는 건지 공백 상태라서 같은 곳을 가리키고 있는 건지 알 수 없다는 것인데 이를 구분하기 위해 삭제 연산에서 추가적인 처리를 해 줄 필요가 있다.
public boolean enQueue(int value) {
if(isFull()) return false;
if(head == -1){
head = 0;
tail = 0;
}
queue[head] = value;
head = (head + 1) % size;
return true;
}
public boolean deQueue() {
if(isEmpty()) return false;
tail = (tail + 1) % size;
if(head == tail) {
head = -1;
tail = -2;
}
return true;
}이를 반영해서 작성한 삽입, 삭제 메서드는 위과 같다. 먼저 삽입 연산을 살펴보자.
삽입 연산인 enQueue() 메서드에서는 isFull() 메서드를 이용해 큐의 포화 상태를 확인하고 있다. 이 메서드는 다음과 같다.
public boolean isFull() {
return head == tail;
}위에서 언급했듯이 head 포인터와 tail 포인터가 만나면 큐가 포화 상태 거나 공백 상태라고 한 점을 반영하여 두 포인터를 비교하고 있는데 여기서는 딱히 포화 상태와 공백 상태를 구분할 수 있는 로직이 보이지 않는다. 그렇다면 어떻게 이 두 포인터를 비교하는 것만으로 포화 상태를 확인할 수 있는 것일까? 말했듯이 삭제 연산에서는 다음과 같은 추가적인 처리를 수행하고 있다.
public boolean deQueue() {
...
if(head == tail) {
head = -1;
tail = -2;
}
...
}삭제 연산에서는 tail 포인터를 증가시키고 있다. 그런데 tail 포인터와 head 포인터가 같은 곳을 가리킨다면 큐의 공백 상태를 의미하기 때문에 이때는 다시 두 포인터를 초기화시켜버린다. 이것이 이 원형 큐의 핵심이다. 흔히 원형 큐를 생각하면 마지막으로 사용한 포인터의 위치는 항상 유지되어야 할 것 같지만 어차피 순차적으로 데이터를 삽입, 삭제하는 것이 목적인 큐 특성상 포인터의 위치는 중요하지 않다. 사실 이 실습에서도 이 고정관념 때문에 애를 많이 먹었다.
public boolean isEmpty() {
return head == -1 && tail == -2;
}그래서 큐의 공백 상태를 검사할 때는 head, tail 포인터가 초기 포인터인 -1, -2를 가리키고 있는지 확인하면 된다. 초기 포인터 값은 딱히 아무런 제한이 없지만 배열에서 참조할 수 없는 값이기만 하면 된다.
public int Front() {
if(isEmpty()) return -1;
return queue[tail];
}
public int Rear() {
if(isEmpty()) return -1;
return queue[(head - 1 + size) % size];
}나머지 연산인 큐의 양쪽 끝 값을 확인하는 메서드는 별로 어려울 게 없다. 차이점은 head 포인터는 삽입 후 새로운 위치로 이동하기 때문에 이전 위치를 참조해야 하지만 tail 포인터는 현재 삭제할 위치를 가리키고 있기 때문에 그대로 반환해도 된다.
자바에서는 Queue 인터페이스를 구현한 LinkedList 클래스를 활용하여 큐를 구현할 수 있다. 이때 Queue 인터페이스에서는 add(), element(), offer(), peek(), poll(), remove() 메서드를 제공하고 있으며 이를 활용하는 예는 다음과 같다.
import java.util.*;
public class Main
{
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList();
queue.add(1);
queue.add(2);
queue.add(3);
queue.add(4);
queue.offer(5);
queue.offer(6);
System.out.println(queue.poll()); // 1
System.out.println(queue.peek()); // 2
queue.remove();
System.out.println(queue.poll()); // 3
System.out.println(queue.poll()); // 4
System.out.println(queue.poll()); // 5
System.out.println(queue.poll()); // 6
System.out.println(queue.poll()); // null
}
}Queue 인터페이스에서는 add() 메서드나 offer() 메서드를 이용하여 값을 삽입할 수 있다. 두 메서드의 차이점은 큐에 들어갈 자리가 없을 경우 IllegalStateException을 발생시키느냐 발생시키지 않느냐의 차이다. 값을 삭제할때는 poll() 메서드를 사용하여 값을 반환받으면서 삭제하거나 peek() 메서드로 값을 반환받기만 할 수도 있다. 값을 삭제할 때는 remove() 메서드를 사용하며 poll() 메서드는 더 이상 반환할 값이 없다면 null을 반환한다.
'자료구조' 카테고리의 다른 글
| Java를 이용한 Circular Deque 구현 (0) | 2021.04.16 |
|---|---|
| Java를 이용한 Stack 실습 (0) | 2021.02.04 |